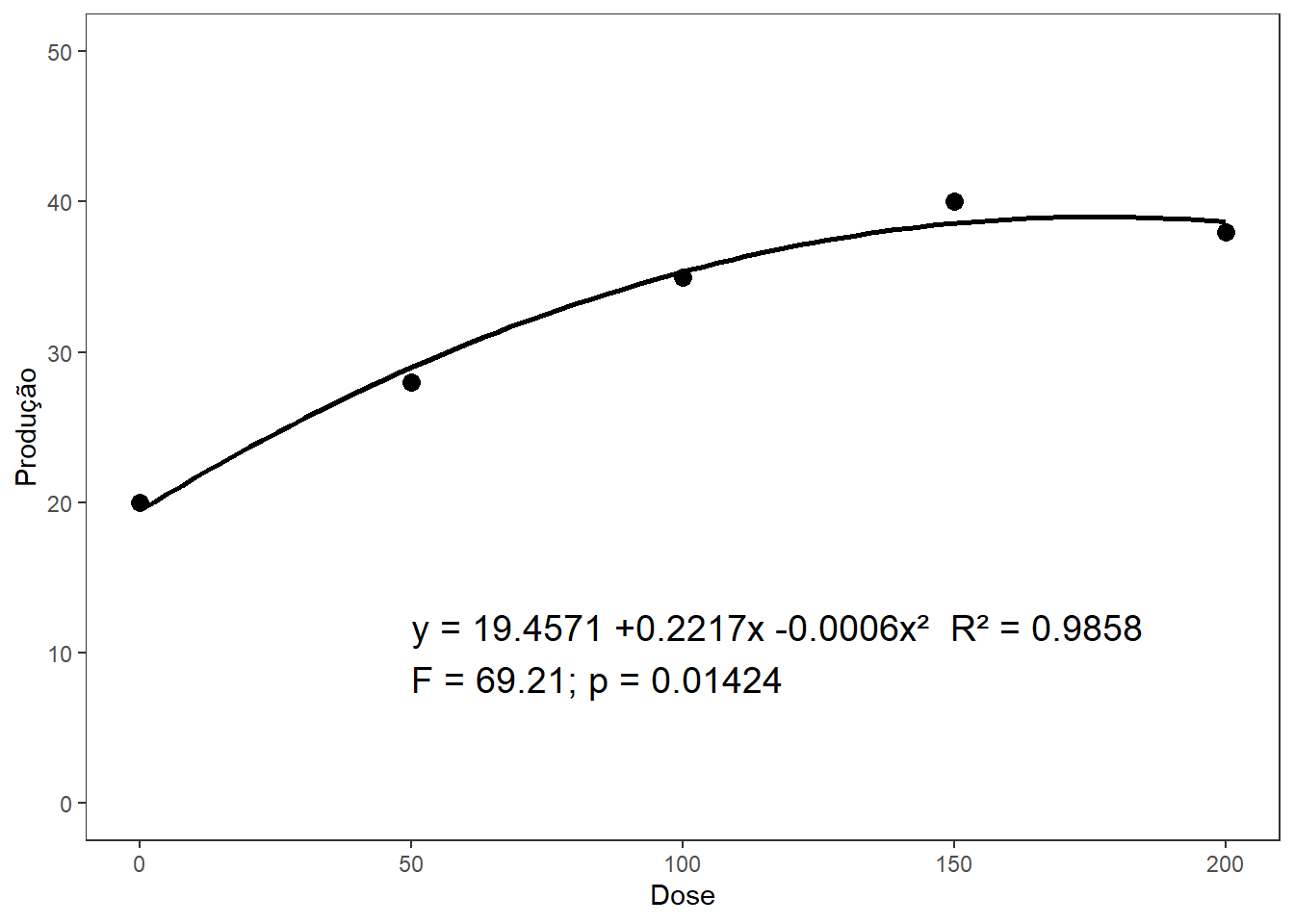🔹 Módulo 1 – Introdução ao R e Organização de Dados
Aula 1 – Instalação e primeiros passos
Instale o R e o RStudio em seu computador.
O R é o programa principal, ou seja, a linguagem de programação e o ambiente de cálculo.
É nele que todos os comandos são processados e as análises estatísticas são realizadas.
Por isso, o primeiro passo é instalar o R no computador.
O download deve ser feito diretamente no site oficial do CRAN (Comprehensive R Archive Network):
Ao abrir o link, basta escolher o sistema operacional do seu computador (Windows, macOS ou Linux) e seguir as instruções de instalação.
Com isso, você já terá o R funcionando, embora a sua interface seja bastante simples e pouco intuitiva para quem está começando.
É justamente nesse ponto que entra o RStudio.
O RStudio não é um programa separado do R, mas sim uma IDE (Integrated Development Environment), ou seja, um ambiente de desenvolvimento que facilita o uso do R.
Ele oferece uma interface gráfica amigável, onde você pode escrever códigos, visualizar gráficos, organizar projetos e instalar pacotes com muito mais facilidade.
No entanto, é fundamental compreender que o RStudio não funciona sozinho.
Ele depende do R já instalado na máquina, pois é o R quem executa de fato os cálculos.
Por isso, a ordem correta é: primeiro instalar o R e, em seguida, instalar o RStudio.
O download do RStudio pode ser feito no site oficial da Posit (empresa responsável pelo software):
Ao instalar os dois programas, você terá o R como motor de cálculo e o RStudio como painel de controle, trabalhando em conjunto.
Essa combinação é a mais utilizada no mundo acadêmico e profissional para análises estatísticas e ciência de dados.
Conheça os principais painéis do RStudio:
Console (execução de comandos)
Source (script)
Environment/History (objetos)
Plots/Packages/Help
Verificando versão do R
# Verificando versão do Rversion
_
platform x86_64-w64-mingw32
arch x86_64
os mingw32
crt ucrt
system x86_64, mingw32
status
major 4
minor 4.2
year 2024
month 10
day 31
svn rev 87279
language R
version.string R version 4.4.2 (2024-10-31 ucrt)
nickname Pile of Leaves
Citando o R
# Citação do Rcitation()
To cite R in publications use:
R Core Team (2024). _R: A Language and Environment for Statistical
Computing_. R Foundation for Statistical Computing, Vienna, Austria.
<https://www.R-project.org/>.
Uma entrada BibTeX para usuários(as) de LaTeX é
@Manual{,
title = {R: A Language and Environment for Statistical Computing},
author = {{R Core Team}},
organization = {R Foundation for Statistical Computing},
address = {Vienna, Austria},
year = {2024},
url = {https://www.R-project.org/},
}
We have invested a lot of time and effort in creating R, please cite it
when using it for data analysis. See also 'citation("pkgname")' for
citing R packages.
Operações simples
# Operações simples## Soma2+2
[1] 4
## Subtração7-2
[1] 5
## Mutiplicação4*3
[1] 12
## Divisão10/3
[1] 3.333333
## Raiz quadradasqrt(25)
[1] 5
Aula 2 – Objetos no R
Nesta aula, aprendemos a criar e manipular objetos no R. Objetos são variáveis que armazenam valores ou resultados de cálculos, permitindo que possamos reutilizá-los em outras operações.
No exemplo apresentado, criamos dois objetos numéricos:
# Criando objetosx <-5y <-10
Aqui, x recebe o valor 5 e y recebe o valor 10. Em seguida, criamos um terceiro objeto chamado soma, que armazena a soma de x e y:
soma <- x + ysoma
[1] 15
Ao digitar apenas soma, o R retorna o valor armazenado neste objeto, que neste caso é 15.
Este exemplo ilustra a forma básica de criar objetos no R e realizar operações simples com eles, fundamental para qualquer análise de dados ou programação no software.
Aula 3 – Pacotes
No R, os pacotes são conjuntos de funções, dados e recursos que estendem as capacidades básicas do software, permitindo realizar análises mais complexas de forma prática e eficiente.
No exemplo abaixo, veja como instalar alguns pacotes importantes um de cada vez:
# Carregando pacotesinstall.packages("tidyverse") # Para manipulação e visualização de dadosinstall.packages("dplyr") # Para manipulação e visualização de dadosinstall.packages("readxl") # Para ler arquivos do Excelinstall.packages("ExpDes.pt") # Para planejamento e análise de experimentos agrícolasinstall.packages("easyanova") # Para facilitar análises de variânciainstall.packages("rstatix") # Para estatísticas descritivas e testes inferenciaisinstall.packages("emmeans") # Para estatísticas descritivas e testes inferenciaisinstall.packages("janitor") # Para limpeza e organização de dadosinstall.packages("kableExtra") # Para tabelas formatadas
Ouse preferir pode instalar vários de uma única vez:
No exemplo abaixo, carregamos alguns pacotes importantes:
# Carregando pacotes# ---------------------------# Pacotes para manipulação e leitura de dados# ---------------------------library(tidyverse) # Inclui dplyr, ggplot2, readr, tidyr, etc.library(dplyr) # Manipulação de dadoslibrary(readxl) # Para importar planilhas Excel# ---------------------------# Pacotes para análise de experimentos# ---------------------------library(ExpDes.pt) # ANOVA para DIC, DBC, parcelas subdivididas etc.library(easyanova) # ANOVA e testes complementares de forma simplificada# ---------------------------# Pacotes para estatística e pós-testes# ---------------------------library(rstatix) # Testes estatísticos (normalidade, homogeneidade, etc.)library(emmeans) # Médias ajustadas e comparações múltiplas# ---------------------------# Pacotes para organização e visualização de dados# ---------------------------library(janitor) # Limpeza e organização de dadoslibrary(kableExtra) # Tabelas formatadas
Aula 4 - Organização e Padronização dos Dados
Um dos passos mais importantes em qualquer análise é a organização adequada dos dados. Dados desorganizados ou com nomes de variáveis inconsistentes podem dificultar o trabalho, aumentar a chance de erros e até inviabilizar o uso de funções em softwares estatísticos como o R.
Veja esse esse exmeplo de banco de dados (dados_ruins_dic) no Excel:
Repetição
Tratamento
Altura da planta (cm)
Matéria seca (g)
T1 - Testemunha
1
160
280
T1 - Testemunha
2
165
300
T1 - Testemunha
3
158
290
T1 - Testemunha
4
162
295
T1 - Testemunha
5
161
285
T2 - 50kg N
1
180
360
T2 - 50kg N
2
185
370
T2 - 50kg N
3
178
365
T2 - 50kg N
4
182
368
T2 - 50kg N
5
184
362
T3 - 100kg N
1
200
450
T3 - 100kg N
2
205
460
T3 - 100kg N
3
198
455
T3 - 100kg N
4
202
465
T3 - 100kg N
5
201
458
T4 - 150kg N
1
220
550
T4 - 150kg N
2
225
560
T4 - 150kg N
3
218
545
T4 - 150kg N
4
222
555
T4 - 150kg N
5
221
548
Importância de bons títulos nas variáveis
No R, os nomes das colunas (ou títulos das variáveis) devem seguir algumas boas práticas para facilitar a análise:
Padrão snake_case: usar letras minúsculas e sublinhados para separar palavras, como altura_planta_g.
Evitar espaços: em vez de Altura da Planta, utilizar Altura_Planta.
Usar unidades no nome da variável: em vez de Altura da Planta (cm), utilizar Altura_Planta_cm.
Importar dados para o R é um passo fundamental para qualquer análise. No R, é possível importar dados de diferentes formatos, o que é essencial para iniciar qualquer análise. O R permite ler diferentes formatos de arquivos, como CSV e Excel.
# Importando CSV# dados_csv <- read.csv("meus_dados.csv", sep = ";", dec = ",")# Lê arquivos CSV, permitindo especificar o separador de colunas (sep) e o separador decimal (dec)# Importando Excel# dados_excel <- readxl::read_excel("meus_dados.xlsx")# Lê planilhas do Excel diretamente para o R# Importando arquivo de texto (TXT)# dados_txt <- read.table("meus_dados.txt", header = TRUE, sep = "\t", dec = ".")# Lê arquivos de texto, onde 'header = TRUE' indica que a primeira linha contém os nomes das colunas,# 'sep = "\t"' indica que as colunas são separadas por tabulação, e 'dec = "."' define o separador decimal
read.csv() lê arquivos no formato CSV (Comma-Separated Values), permitindo especificar o separador de colunas (sep) e o separador decimal (dec). É indicado para planilhas exportadas como CSV ou dados gerados por outros programas.
read_excel() (do pacote readxl) lê arquivos do Excel (.xls ou .xlsx) diretamente, mantendo nomes das colunas e tipos de dados corretamente, o que facilita a importação de planilhas complexas sem precisar convertê-las.
read.table() lê arquivos de texto simples (TXT ou outros delimitados), oferecendo flexibilidade para especificar se há cabeçalho (header = TRUE), o separador de colunas (sep) e o separador decimal (dec). É ideal para arquivos de texto com diferentes formatos de separação.
Visualizando os dados
Após a importação, podemos visualizar os dados para verificar se foram carregados corretamente: Após a importação, é importante visualizar os dados para conferir se foram carregados corretamente. Para isso, podem ser usadas funções como:
head() (exibe as primeiras linhas),
summary() (mostra resumo estatístico das variáveis),
str() (mostra a estrutura do objeto) e
glimpse() (exibe de forma compacta e legível a estrutura e os tipos das variáveis).
# head(dados_csv) # Mostra as primeiras linhas do conjunto de dados# summary(dados_csv) # Mostra um resumo estatístico das variáveis# str(dados_csv) # Mostra a estrutura do objeto, incluindo tipos de variáveis e dimensões# glimpse(dados_csv) # Mostra todas as variáveis, seus tipos e algumas observações de cada coluna
🔹 Módulo 2 – Manipulação e Exploração de Dados
Aula 6 – Tipos de Variáveis em R
Variáveis numéricas
Contínuas (numeric / dbl): podem assumir qualquer valor dentro de um intervalo, incluindo decimais. Exemplo: Produtividade (t/ha), Área (m²)
Discretas (integer / int): assumem apenas valores inteiros. Exemplo: Parcela (identificador das parcelas)
Variáveis categóricas (fatores) (factor / fct)
Representam categorias ou grupos que o R reconhece para análises estatísticas. Exemplo: Tratamento, Variedade
Ideais para análise de variância e comparações entre grupos
Variáveis de texto (character / chr)
Contêm informações textuais ou descritivas, que não têm ordem ou significado numérico. Exemplo: Local (Norte, Sul, Leste)
Não são usadas diretamente em cálculos estatísticos, mas servem para identificar ou agrupar dados
Variáveis lógicas (logical / logi)
Assumem apenas dois valores: TRUE ou FALSE Exemplo: Irrigado
Úteis para condições, filtros e análises condicionais
Outros tipos disponíveis em R
Complexo (complex / sem abreviação comum): números complexos, como 1+2i
Raw (raw / sem abreviação comum): representa dados brutos em bytes
Date (Date / sem abreviação comum): datas no formato "YYYY-MM-DD"
POSIXct / POSIXlt (POSIXct / POSIXlt): datas e horas com tempo
Ordered factor (ordered / ord): fatores com ordem natural definida
Neste exemplo, iremos criar variáveis de diferentes tipos em R — numéricas contínuas, numéricas discretas e categóricas (fatores) — e, em seguida, identificar o tipo de cada variável usando a função class().
Isso nos permite compreender como o R armazena cada tipo de dado e como ele será tratado em análises estatísticas.
Neste exemplo, iremos criar um banco de dados fictício de um experimento agrícola com diferentes tipos de variáveis: numéricas (contínuas e discretas), categóricas, lógicas e de texto.
Em seguida, iremos visualizar o banco de dados e identificar os tipos de variáveis, para entender como o R armazena cada tipo e como podemos manipulá-las em análises estatísticas.
Funções para Visualização e Estrutura de Dados no R
head(dados_agro)
Mostra as primeiras linhas do conjunto de dados.
Útil para ter uma visão rápida do conteúdo do banco, verificando se os dados foram importados corretamente.
Exemplo de saída:
head(dados_agro)
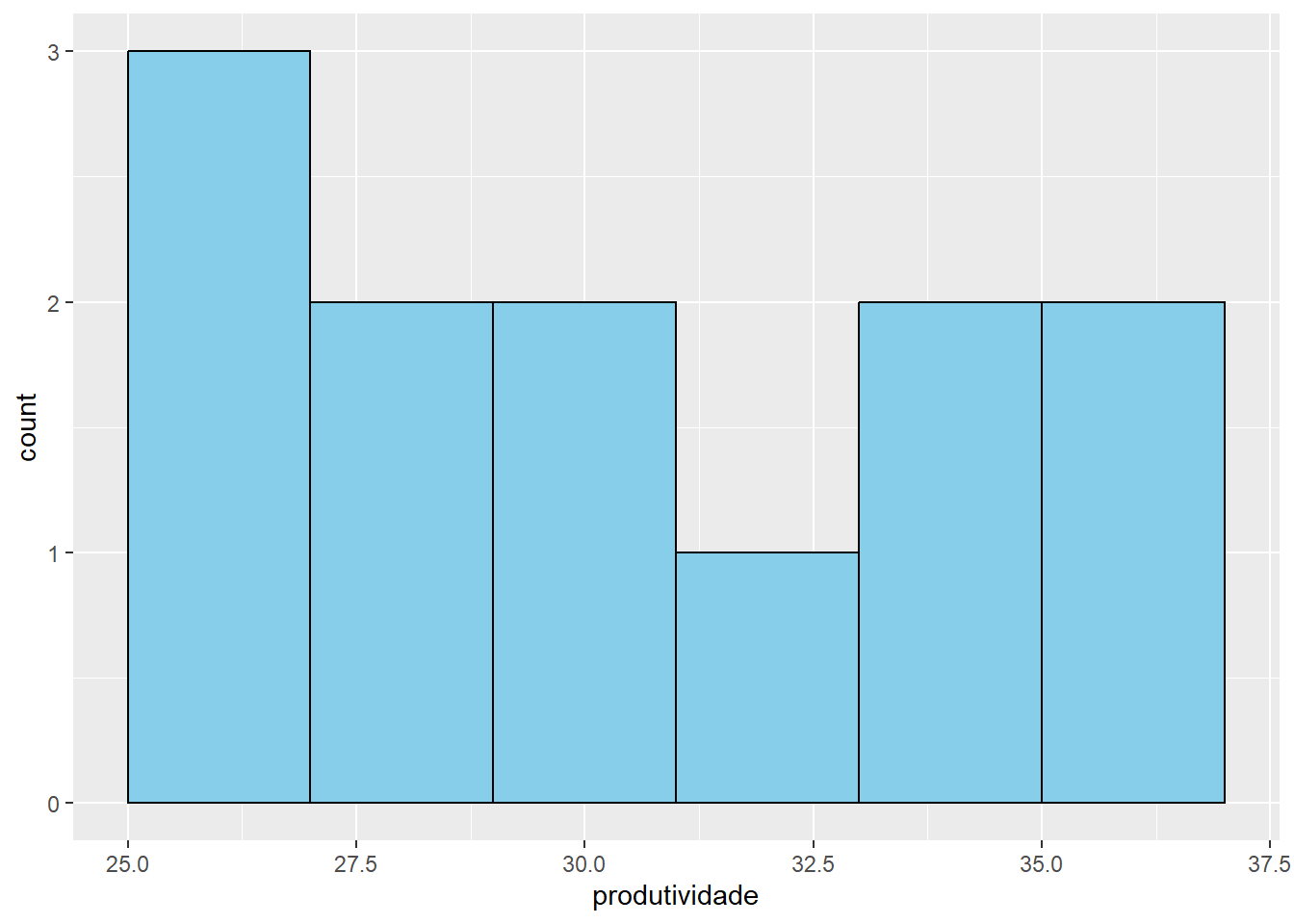
Parcela Tratamento Variedade Area Produtividade Irrigado Local
1 1 T1 A 10 30.5 TRUE Norte
2 2 T1 A 10 32.0 TRUE Norte
3 3 T1 A 10 31.0 TRUE Norte
4 4 T2 B 12 28.0 FALSE Sul
5 5 T2 B 12 29.5 FALSE Sul
6 6 T2 B 12 30.0 FALSE Sul
str(dados_agro)
Mostra a estrutura do objeto, permitindo entender rapidamente como os dados estão organizados no R.
Com essa função, é possível:
Ver o número de observações (linhas) e o número de variáveis (colunas) do banco de dados, por exemplo, 9 obs. of 7 variables.
Identificar o tipo de cada variável, como int (inteiro), num (numérico contínuo), Factor (categórica), logi (lógica/boolean) e chr (texto).
Conferir alguns valores iniciais de cada coluna, ajudando a verificar se os dados foram importados corretamente e se os tipos estão adequados para análise.
Em resumo, str() é uma função essencial para inspecionar rapidamente a estrutura e os tipos das variáveis, antes de realizar qualquer análise estatística ou manipulação dos dados.
str(dados_agro)
'data.frame': 9 obs. of 7 variables:
$ Parcela : int 1 2 3 4 5 6 7 8 9
$ Tratamento : chr "T1" "T1" "T1" "T2" ...
$ Variedade : chr "A" "A" "A" "B" ...
$ Area : num 10 10 10 12 12 12 11 11 11
$ Produtividade: num 30.5 32 31 28 29.5 30 33 34.5 32.5
$ Irrigado : logi TRUE TRUE TRUE FALSE FALSE FALSE ...
$ Local : chr "Norte" "Norte" "Norte" "Sul" ...
Observe que Tratamento e Variedade aparecem como character, ou seja, texto.
Para análises estatísticas, é recomendado transformar essas variáveis em fatores.
summary(dados_agro)
Mostra um resumo estatístico das variáveis:
- Para variáveis numéricas: mínimo, máximo, média, quartis
- Para fatores: contagem de cada nível
- Para lógicas: contagem de TRUE e FALSE
- Útil para identificar tendências, valores extremos e distribuição dos dados.
summary(dados_agro)
Parcela Tratamento Variedade Area Produtividade
Min. :1 Length:9 Length:9 Min. :10 Min. :28.00
1st Qu.:3 Class :character Class :character 1st Qu.:10 1st Qu.:30.00
Median :5 Mode :character Mode :character Median :11 Median :31.00
Mean :5 Mean :11 Mean :31.22
3rd Qu.:7 3rd Qu.:12 3rd Qu.:32.50
Max. :9 Max. :12 Max. :34.50
Irrigado Local
Mode :logical Length:9
FALSE:3 Class :character
TRUE :6 Mode :character
Veja novamente que Tratamento e Variedade aparecem como character.
E não são reconhecidas como fatores.
E não é possível perceber quais são os níveis de cada variável categórica.
Convertendo variaveis categóricas em fatores
Pode-se convertê-las em fatores usando a função as.factor():
Agora sim, Tratamento e variedade aparecem como Factor com 3 níveis cada.
veja como fica o resumo estatístico dos dados:
summary(dados_agro)
Parcela Tratamento Variedade Area Produtividade Irrigado
Min. :1 T1:3 A:3 Min. :10 Min. :28.00 Mode :logical
1st Qu.:3 T2:3 B:3 1st Qu.:10 1st Qu.:30.00 FALSE:3
Median :5 T3:3 C:3 Median :11 Median :31.00 TRUE :6
Mean :5 Mean :11 Mean :31.22
3rd Qu.:7 3rd Qu.:12 3rd Qu.:32.50
Max. :9 Max. :12 Max. :34.50
Local
Length:9
Class :character
Mode :character
Agora é possível ver a contagem de cada nível das variáveis categóricas. Ou seja, são 3 níveis em cada variável (T1, T2, T3 para Tratamento e A, B, C para Variedade).
Pode-se convertê-las em fatores usando a função factor():
Também dá para criar o fator diretamente com a função factor(), que é mais flexível porque permite:
Definir os níveis (levels)
Definir as etiquetas (labels)
Ou seja, permite controlar a ordem e o rótulo dos níveis (mais recomendado para ANOVA e modelos, pois evita ordem alfabética indesejada).
Pode-se ainda convertê-las em fatores usando a função convert_as_factor() do pacote {rstatix}:
A função convert_as_factor() pode converter uma ou várias colunas ao mesmo tempo.
glimpse(dados_agro) (do pacote dplyr)
Mostra a estrutura dos dados de forma compacta e legível, similar ao str(), mas em formato horizontal:
Exibe todas as variáveis, seus tipos e algumas observações iniciais
Mais fácil de ler quando o banco de dados tem muitas colunas
------------------------------------------------------------------------
Quadro da analise de variancia
------------------------------------------------------------------------
GL SQ QM Fc Pr>Fc
Tratamento 2 163.50 81.750 39.24 3.5934e-05
Residuo 9 18.75 2.083
Total 11 182.25
------------------------------------------------------------------------
CV = 4.69 %
------------------------------------------------------------------------
Teste de normalidade dos residuos ( Shapiro-Wilk )
Valor-p: 0.5375769
De acordo com o teste de Shapiro-Wilk a 5% de significancia, os residuos podem ser considerados normais.
------------------------------------------------------------------------
------------------------------------------------------------------------
Teste de homogeneidade de variancia
valor-p: 0.8663487
De acordo com o teste de bartlett a 5% de significancia, as variancias podem ser consideradas homogeneas.
------------------------------------------------------------------------
Teste de Tukey
------------------------------------------------------------------------
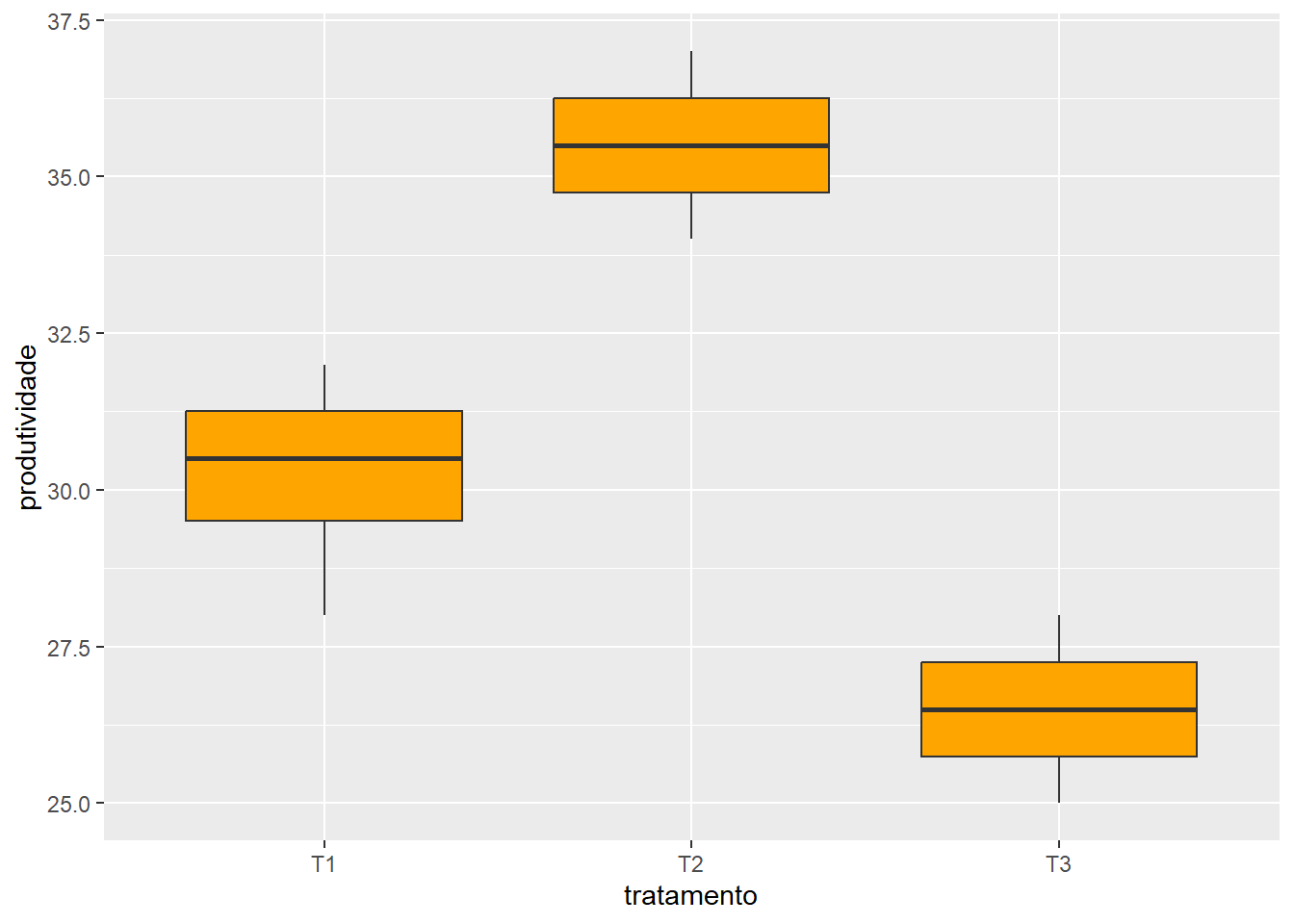
Grupos Tratamentos Medias
a T2 35.5
b T1 30.25
c T3 26.5
------------------------------------------------------------------------
$`Analysis of variance`
df type I SS mean square F value p>F
treatments 2 163.50 81.7500 39.24 <0.001
Residuals 9 18.75 2.0833 - -
$Means
treatment mean sd sem min max tukey snk duncan t scott_knott
1 T2 35.50 1.2910 0.7217 34 37 a a a a a
2 T1 30.25 1.7078 0.7217 28 32 b b b b b
3 T3 26.50 1.2910 0.7217 25 28 c c c c c
$`Multiple comparison test`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 T2 - T1 5.25 0.0016 0.0006 0.0006 0.0006
2 T2 - T3 9.00 0.0000 0.0000 0.0000 0.0000
3 T1 - T3 3.75 0.0128 0.0051 0.0051 0.0051
$`Residual analysis`
$`Residual analysis`$`residual analysis`
values
p.value Shapiro-Wilk test 0.5376
p.value Bartlett test 0.8663
coefficient of variation (%) 4.6900
first value most discrepant 3.0000
second value most discrepant 2.0000
third value most discrepant 8.0000
$`Residual analysis`$residuals
1 2 3 4 5 6 7 8 9 10 11 12
-0.25 1.75 -2.25 0.75 -0.50 0.50 -1.50 1.50 -1.50 0.50 -0.50 1.50
$`Residual analysis`$`standardized residuals`
1 2 3 4 5 6 7
-0.1914854 1.3403980 -1.7233688 0.5744563 -0.3829708 0.3829708 -1.1489125
8 9 10 11 12
1.1489125 -1.1489125 0.3829708 -0.3829708 1.1489125
Testes de Pressupostos
Antes da análise de variância (ANOVA), foi realizada a verificação dos pressupostos de normalidade dos resíduos e homogeneidade das variâncias, que são condições necessárias para a validade do teste F.
Normalidade dos resíduos
O teste de Shapiro-Wilk foi aplicado sobre os resíduos do modelo, verificando se a distribuição se aproxima da normal.
Além disso, a normalidade foi testada dentro de cada grupo experimental utilizando a função shapiro_test() do pacote rstatix, o que permite avaliar possíveis desvios em tratamentos específicos.
Quando o valor de p > 0,05, não se rejeita a hipótese nula de normalidade, indicando que os resíduos podem ser considerados normalmente distribuídos.
# Normalidadeshapiro.test(residuals(modelo))
Shapiro-Wilk normality test
data: residuals(modelo)
W = 0.94298, p-value = 0.5376
# Usando pacote rstatix e fazendo normalidade por grupodados |>group_by(tratamento) |> rstatix::shapiro_test(produtividade)
# A tibble: 3 × 4
tratamento variable statistic p
<fct> <chr> <dbl> <dbl>
1 T1 produtividade 0.971 0.850
2 T2 produtividade 0.993 0.972
3 T3 produtividade 0.993 0.972
Homogeneidade das variâncias
Para verificar se os tratamentos apresentam variâncias homogêneas, foram aplicados três testes:
Teste de Bartlett: sensível a desvios de normalidade, mas adequado quando os dados são normais.
Teste de Levene: mais robusto quando a normalidade não é estritamente atendida.
# Homogeneidade## Teste de Bartlettbartlett.test(produtividade ~ tratamento, data = dados)
Bartlett test of homogeneity of variances
data: produtividade by tratamento
Bartlett's K-squared = 0.28694, df = 2, p-value = 0.8663
## Teste de Levenerstatix::levene_test(produtividade ~ tratamento, data = dados)
# A tibble: 1 × 4
df1 df2 statistic p
<int> <int> <dbl> <dbl>
1 2 9 0.158 0.856
Em todos os testes, valores de p > 0,05 indicam que não há evidências para rejeitar a hipótese de homogeneidade das variâncias, atendendo ao pressuposto da ANOVA.
Dessa forma, a análise de variância pode ser conduzida com confiança, uma vez que os pressupostos de normalidade e homogeneidade foram verificados.
Comparações de Médias
# Tukey no R baseTukeyHSD(modelo)
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = produtividade ~ tratamento, data = dados)
$tratamento
diff lwr upr p adj
T2-T1 5.25 2.400421 8.0995788 0.0015767
T3-T1 -3.75 -6.599579 -0.9004212 0.0127984
T3-T2 -9.00 -11.849579 -6.1504212 0.0000269
# Tukey no rstatixdados |>tukey_hsd(produtividade ~ tratamento)
Note: adjust = "tukey" was changed to "sidak"
because "tukey" is only appropriate for one set of pairwise comparisons
print(grupos)
tratamento emmean SE df lower.CL upper.CL .group
T3 26.5 0.722 9 24.4 28.6 a
T1 30.2 0.722 9 28.1 32.4 b
T2 35.5 0.722 9 33.4 37.6 c
Confidence level used: 0.95
Conf-level adjustment: sidak method for 3 estimates
P value adjustment: tukey method for comparing a family of 3 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
Aula 10 – ANOVA em DBC
Anova
No DBC (delineamento em blocos casualizados) a diferença principal é que você precisa considerar o efeito de blocos no modelo. Seguindo o mesmo estilo da sua aula de DIC, aqui está a versão para DBC:
# ANOVA usando aov()# Aqui usamos Error(bloco) ou bloco como efeitomodelo <-aov(produtividade ~ tratamento + repeticao, data = dados)summary(modelo)
------------------------------------------------------------------------
Quadro da analise de variancia
------------------------------------------------------------------------
GL SQ QM Fc Pr>Fc
Tratamento 2 163.500 81.750 127.957 0.000012
Bloco 3 14.917 4.972 7.783 0.017195
Residuo 6 3.833 0.639
Total 11 182.250
------------------------------------------------------------------------
CV = 2.6 %
------------------------------------------------------------------------
Teste de normalidade dos residuos
valor-p: 0.4793843
De acordo com o teste de Shapiro-Wilk a 5% de significancia, os residuos podem ser considerados normais.
------------------------------------------------------------------------
------------------------------------------------------------------------
Teste de homogeneidade de variancia
valor-p: 0.1530654
De acordo com o teste de oneillmathews a 5% de significancia, as variancias podem ser consideradas homogeneas.
------------------------------------------------------------------------
Teste de Tukey
------------------------------------------------------------------------
Grupos Tratamentos Medias
a T2 35.5
b T1 30.25
c T3 26.5
------------------------------------------------------------------------
$`Analysis of variance`
df type III SS mean square F value p>F
treatments 2 163.5000 81.7500 127.9565 <0.001
blocks 3 14.9167 4.9722 7.7826 0.0172
residuals 6 3.8333 0.6389 - -
$`Adjusted means`
treatment adjusted.mean sd sem min max tukey snk duncan t scott_knott
1 T2 35.50 1.2910 0.3997 34 37 a a a a a
2 T1 30.25 1.7078 0.3997 28 32 b b b b b
3 T3 26.50 1.2910 0.3997 25 28 c c c c c
$`Multiple comparison test`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 T2 - T1 5.25 0.0002 1e-04 1e-04 1e-04
2 T2 - T3 9.00 0.0000 0e+00 0e+00 0e+00
3 T1 - T3 3.75 0.0014 6e-04 6e-04 6e-04
$`Residual analysis`
$`Residual analysis`$`residual analysis`
values
p.value Shapiro-Wilk test 0.4794
p.value Bartlett test 0.8663
coefficient of variation (%) 2.6000
first value most discrepant 11.0000
second value most discrepant 3.0000
third value most discrepant 2.0000
$`Residual analysis`$residuals
1 2 3 4 5 6
0.50000000 0.83333333 -0.83333333 -0.50000000 0.25000000 -0.41666667
7 8 9 10 11 12
-0.08333333 0.25000000 -0.75000000 -0.41666667 0.91666667 0.25000000
$`Residual analysis`$`standardized residuals`
1 2 3 4 5 6 7
0.8469896 1.4116493 -1.4116493 -0.8469896 0.4234948 -0.7058246 -0.1411649
8 9 10 11 12
0.4234948 -1.2704843 -0.7058246 1.5528142 0.4234948
Observações importantes:
No aov(), o termo + bloco garante que a variação entre blocos seja considerada.
No ExpDes.pt, usamos dbc() no lugar de dic().
No easyanova, o argumento design = 2 é usado para DBC.
Testes de Pressupostos
# Normalidadeshapiro.test(residuals(modelo))
Shapiro-Wilk normality test
data: residuals(modelo)
W = 0.93854, p-value = 0.4794
# Usando pacote rstatix e fazendo normalidade por grupodados |>group_by(tratamento) |> rstatix::shapiro_test(produtividade)
# A tibble: 3 × 4
tratamento variable statistic p
<fct> <chr> <dbl> <dbl>
1 T1 produtividade 0.971 0.850
2 T2 produtividade 0.993 0.972
3 T3 produtividade 0.993 0.972
# Homogeneidade## Teste de Bartlettbartlett.test(produtividade ~ tratamento, data = dados)
Bartlett test of homogeneity of variances
data: produtividade by tratamento
Bartlett's K-squared = 0.28694, df = 2, p-value = 0.8663
## Teste de Levenerstatix::levene_test(produtividade ~ tratamento, data = dados)
# A tibble: 1 × 4
df1 df2 statistic p
<int> <int> <dbl> <dbl>
1 2 9 0.158 0.856
## Teste de ONeill e Mathewsoneilldbc(trat = dados$tratamento, resp = dados$produtividade, bloco = dados$repeticao)
[1] 0.1530654
Em DBC também foi realizado Teste de O’Neill e Mathews, específico para experimentos em blocos casualizados (DBC), sendo recomendado como alternativa robusta para esse delineamento.
Em todos os testes, valores de p > 0,05 indicam que não há evidências para rejeitar a hipótese de homogeneidade das variâncias, atendendo ao pressuposto da ANOVA.
Note: adjust = "tukey" was changed to "sidak"
because "tukey" is only appropriate for one set of pairwise comparisons
print(grupos)
tratamento emmean SE df lower.CL upper.CL .group
T3 26.5 0.4 6 25.2 27.8 a
T1 30.2 0.4 6 28.9 31.6 b
T2 35.5 0.4 6 34.2 36.8 c
Results are averaged over the levels of: repeticao
Confidence level used: 0.95
Conf-level adjustment: sidak method for 3 estimates
P value adjustment: tukey method for comparing a family of 3 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same.
Aula 11 – ANOVA Fatorial em DIC
# Exemplo com dois fatoresdados2 <-expand.grid(adubacao =c("A1", "A2"),cultivar =c("C1", "C2", "C3"),rep =1:4)set.seed(123)dados2$produtividade <-rnorm(24, mean =30, sd =3)dados2$adubacao <-factor(dados2$adubacao)dados2$cultivar <-factor(dados2$cultivar)dados2$rep <-factor(dados2$rep)# ANOVA usando aov()modelo2 <-aov(produtividade ~ adubacao * cultivar, data = dados2)summary(modelo2)
Df Sum Sq Mean Sq F value Pr(>F)
adubacao 1 2.09 2.089 0.217 0.647
cultivar 2 1.07 0.536 0.056 0.946
adubacao:cultivar 2 13.72 6.861 0.712 0.504
Residuals 18 173.43 9.635
------------------------------------------------------------------------
Legenda:
FATOR 1: F1
FATOR 2: F2
------------------------------------------------------------------------
Quadro da analise de variancia
------------------------------------------------------------------------
GL SQ QM Fc Pr>Fc
F1 1 2.089 3 0.21680 0.64708
F2 2 1.073 2 0.05566 0.94602
F1*F2 2 13.723 4 0.71212 0.50391
Residuo 18 173.435 5
Total 23 190.319 1
------------------------------------------------------------------------
CV = 10.36 %
------------------------------------------------------------------------
Teste de normalidade dos residuos (Shapiro-Wilk)
valor-p: 0.6606527
De acordo com o teste de Shapiro-Wilk a 5% de significancia, os residuos podem ser considerados normais.
------------------------------------------------------------------------
Interacao nao significativa: analisando os efeitos simples
------------------------------------------------------------------------
F1
De acordo com o teste F, as medias desse fator sao estatisticamente iguais.
------------------------------------------------------------------------
Niveis Medias
1 A1 30.26899
2 A2 29.67895
------------------------------------------------------------------------
F2
De acordo com o teste F, as medias desse fator sao estatisticamente iguais.
------------------------------------------------------------------------
Niveis Medias
1 C1 29.67946
2 C2 30.16574
3 C3 30.07672
------------------------------------------------------------------------
$`Analysis of variance`
df type III SS mean square F value p>F
factor_1 1 2.0889 2.0889 0.2168 0.6471
factor_2 2 1.0726 0.5363 0.0557 0.946
factor_1:factor_2 2 13.7229 6.8614 0.7121 0.5039
residuals 18 173.4346 9.6353 - -
$`Adjusted means (factor 1)`
factor_1 adjusted.mean sd sem tukey snk duncan t scott_knott
1 A1 30.269 2.5979 0.8961 a a a a a
2 A2 29.679 3.2191 0.8961 a a a a a
$`Multiple comparison test (factor 1)`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1 - A2 0.59 0.6471 0.6471 0.6471 0.6471
$`Adjusted means (factor 2)`
factor_2 adjusted.mean sd sem tukey snk duncan t scott_knott
1 C2 30.1657 3.1608 1.0975 a a a a a
2 C3 30.0767 3.6356 1.0975 a a a a a
3 C1 29.6795 1.9564 1.0975 a a a a a
$`Multiple comparison test (factor 2)`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 C2 - C3 0.0890 0.9982 0.9549 0.9549 0.9549
2 C2 - C1 0.4862 0.9475 0.9475 0.7709 0.7577
3 C3 - C1 0.3972 0.9646 0.8009 0.8009 0.8009
$`Adjusted means (factor 1 in levels of factor 2)`
$`Adjusted means (factor 1 in levels of factor 2)`$`factor_1 in C1`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
1 A1.C1 30.7519 1.6684 1.552 a a a a a
2 A2.C1 28.6070 1.7550 1.552 a a a a a
$`Adjusted means (factor 1 in levels of factor 2)`$`factor_1 in C2`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
4 A2.C2 30.8953 3.0436 1.552 a a a a a
3 A1.C2 29.4361 3.5536 1.552 a a a a a
$`Adjusted means (factor 1 in levels of factor 2)`$`factor_1 in C3`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
5 A1.C3 30.6189 2.8171 1.552 a a a a a
6 A2.C3 29.5345 4.7032 1.552 a a a a a
$`Multiple comparison test (factor 1 in levels of factor 2)`
$`Multiple comparison test (factor 1 in levels of factor 2)`$`factor_1 in C1`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1.C1 - A2.C1 2.1449 0.3414 0.3414 0.3414 0.3414
$`Multiple comparison test (factor 1 in levels of factor 2)`$`factor_1 in C2`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A2.C2 - A1.C2 1.4592 0.5146 0.5146 0.5146 0.5146
$`Multiple comparison test (factor 1 in levels of factor 2)`$`factor_1 in C3`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1.C3 - A2.C3 1.0844 0.6272 0.6272 0.6272 0.6272
$`Adjusted means (factor 2 in levels of factor 1)`
$`Adjusted means (factor 2 in levels of factor 1)`$`factor_2 in A1`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
1 A1.C1 30.7519 1.6684 1.552 a a a a a
5 A1.C3 30.6189 2.8171 1.552 a a a a a
3 A1.C2 29.4361 3.5536 1.552 a a a a a
$`Adjusted means (factor 2 in levels of factor 1)`$`factor_2 in A2`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
4 A2.C2 30.8953 3.0436 1.552 a a a a a
6 A2.C3 29.5345 4.7032 1.552 a a a a a
2 A2.C1 28.6070 1.7550 1.552 a a a a a
$`Multiple comparison test (factor 2 in levels of factor 1)`
$`Multiple comparison test (factor 2 in levels of factor 1)`$`factor_2 in A1`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1.C1 - A1.C3 0.1330 0.9980 0.9523 0.9523 0.9523
2 A1.C1 - A1.C2 1.3158 0.8221 0.8221 0.5783 0.5563
3 A1.C3 - A1.C2 1.1828 0.8533 0.5966 0.5966 0.5966
$`Multiple comparison test (factor 2 in levels of factor 1)`$`factor_2 in A2`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A2.C2 - A2.C3 1.3608 0.8112 0.5430 0.5430 0.5430
2 A2.C2 - A2.C1 2.2883 0.5605 0.5605 0.3371 0.3109
3 A2.C3 - A2.C1 0.9275 0.9068 0.6776 0.6776 0.6776
$`Residual analysis`
$`Residual analysis`$`residual analysis`
values
p.value Shapiro-Wilk test 0.6607
p.value Bartlett test (factor_1) 0.5289
p.value Bartlett test (factor_2) 0.1309
p.value Bartlett test (treatments) 0.5464
coefficient of variation (%) 10.3600
first value most discrepant 6.0000
second value most discrepant 18.0000
third value most discrepant 3.0000
$`Residual analysis`$residuals
1 2 3 4 5 6
-2.43335287 0.70247809 5.23998198 -0.68381331 -0.23104847 5.61066714
7 8 9 10 11 12
0.63082268 -2.40217314 -1.49670152 -2.23232439 3.05333372 1.54491366
13 14 15 16 17 18
0.45038842 1.72505871 -1.10366637 4.46540093 0.87463976 -5.43437929
19 20 21 22 23 24
1.35214177 -0.02536366 -2.63961408 -1.54926323 -3.69692502 -1.72120151
$`Residual analysis`$`standardized residuals`
1 2 3 4 5 6
-0.886137644 0.255816692 1.908208766 -0.249019664 -0.084139356 2.043198673
7 8 9 10 11 12
0.229722427 -0.874783133 -0.545043662 -0.812930463 1.111911873 0.562600750
13 14 15 16 17 18
0.164014901 0.628202953 -0.401914711 1.626134829 0.318511642 -1.979001121
19 20 21 22 23 24
0.492400316 -0.009236513 -0.961250393 -0.564184702 -1.346284159 -0.626798303
Aula 12 – ANOVA Fatorial em DBC
# ANOVA usando aov()# Aqui, bloco é adicionado como efeito de erromodelo_dbc <-aov(produtividade ~ rep + adubacao * cultivar, data = dados2)summary(modelo_dbc)
Df Sum Sq Mean Sq F value Pr(>F)
rep 3 22.94 7.647 0.762 0.533
adubacao 1 2.09 2.089 0.208 0.655
cultivar 2 1.07 0.536 0.053 0.948
adubacao:cultivar 2 13.72 6.861 0.684 0.520
Residuals 15 150.49 10.033
# ExpDes.pt# fat2.dbc é a função para fatorial em blocos no pacote ExpDes.ptfat2.dbc(bloco = dados2$rep,fator1 = dados2$adubacao,fator2 = dados2$cultivar,resp = dados2$produtividade,quali =c(TRUE, TRUE),mcomp ="tukey")
------------------------------------------------------------------------
Legenda:
FATOR 1: F1
FATOR 2: F2
------------------------------------------------------------------------
Quadro da analise de variancia
------------------------------------------------------------------------
GL SQ QM Fc Pr>Fc
Bloco 3 22.942 6 0.76223 0.53264
F1 1 2.089 4 0.20821 0.65471
F2 2 1.073 2 0.05345 0.94813
F1*F2 2 13.723 5 0.68390 0.51971
Residuo 15 150.493 3
Total 23 190.319 1
------------------------------------------------------------------------
CV = 10.57 %
------------------------------------------------------------------------
Teste de normalidade dos residuos (Shapiro-Wilk)
valor-p: 0.6960048
De acordo com o teste de Shapiro-Wilk a 5% de significancia, os residuos podem ser considerados normais.
------------------------------------------------------------------------
Interacao nao significativa: analisando os efeitos simples
------------------------------------------------------------------------
F1
De acordo com o teste F, as medias desse fator sao estatisticamente iguais.
------------------------------------------------------------------------
Niveis Medias
1 A1 30.26899
2 A2 29.67895
------------------------------------------------------------------------
F2
De acordo com o teste F, as medias desse fator sao estatisticamente iguais.
------------------------------------------------------------------------
Niveis Medias
1 C1 29.67946
2 C2 30.16574
3 C3 30.07672
------------------------------------------------------------------------
# easyanova# Em DBC, design = 2 (fatorial em blocos)easyanova::ea2(dados2, design =2, plot =2)
$`Analysis of variance`
df type III SS mean square F value p>F
factor_1 1 2.0889 2.0889 0.2082 0.6547
factor_2 2 1.0726 0.5363 0.0535 0.9481
blocks 3 22.9420 7.6473 0.7622 0.5326
factor_1:factor_2 2 13.7229 6.8614 0.6839 0.5197
residuals 15 150.4926 10.0328 - -
$`Adjusted means (factor 1)`
factor_1 adjusted.mean sd sem tukey snk duncan t scott_knott
1 A1 30.269 2.5979 0.9144 a a a a a
2 A2 29.679 3.2191 0.9144 a a a a a
$`Multiple comparison test (factor 1)`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1 - A2 0.59 0.6547 0.6547 0.6547 0.6547
$`Adjusted means (factor 2)`
factor_2 adjusted.mean sd sem tukey snk duncan t scott_knott
1 C2 30.1657 3.1608 1.1199 a a a a a
2 C3 30.0767 3.6356 1.1199 a a a a a
3 C1 29.6795 1.9564 1.1199 a a a a a
$`Multiple comparison test (factor 2)`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 C2 - C3 0.0890 0.9983 0.9559 0.9559 0.9559
2 C2 - C1 0.4862 0.9495 0.9495 0.7754 0.7631
3 C3 - C1 0.3972 0.9660 0.8054 0.8054 0.8054
$`Adjusted means (factor 1 in levels of factor 2)`
$`Adjusted means (factor 1 in levels of factor 2)`$`factor_1 in C1`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
1 A1.C1 30.7519 1.6684 1.5837 a a a a a
2 A2.C1 28.6070 1.7550 1.5837 a a a a a
$`Adjusted means (factor 1 in levels of factor 2)`$`factor_1 in C2`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
4 A2.C2 30.8953 3.0436 1.5837 a a a a a
3 A1.C2 29.4361 3.5536 1.5837 a a a a a
$`Adjusted means (factor 1 in levels of factor 2)`$`factor_1 in C3`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
5 A1.C3 30.6189 2.8171 1.5837 a a a a a
6 A2.C3 29.5345 4.7032 1.5837 a a a a a
$`Multiple comparison test (factor 1 in levels of factor 2)`
$`Multiple comparison test (factor 1 in levels of factor 2)`$`factor_1 in C1`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1.C1 - A2.C1 2.1449 0.3534 0.3534 0.3534 0.3534
$`Multiple comparison test (factor 1 in levels of factor 2)`$`factor_1 in C2`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A2.C2 - A1.C2 1.4592 0.5246 0.5246 0.5246 0.5246
$`Multiple comparison test (factor 1 in levels of factor 2)`$`factor_1 in C3`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1.C3 - A2.C3 1.0844 0.6353 0.6353 0.6353 0.6353
$`Adjusted means (factor 2 in levels of factor 1)`
$`Adjusted means (factor 2 in levels of factor 1)`$`factor_2 in A1`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
1 A1.C1 30.7519 1.6684 1.5837 a a a a a
5 A1.C3 30.6189 2.8171 1.5837 a a a a a
3 A1.C2 29.4361 3.5536 1.5837 a a a a a
$`Adjusted means (factor 2 in levels of factor 1)`$`factor_2 in A2`
treatment adjusted.mean sd sem tukey snk duncan t scott_knott
4 A2.C2 30.8953 3.0436 1.5837 a a a a a
6 A2.C3 29.5345 4.7032 1.5837 a a a a a
2 A2.C1 28.6070 1.7550 1.5837 a a a a a
$`Multiple comparison test (factor 2 in levels of factor 1)`
$`Multiple comparison test (factor 2 in levels of factor 1)`$`factor_2 in A1`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A1.C1 - A1.C3 0.1330 0.9981 0.9534 0.9534 0.9534
2 A1.C1 - A1.C2 1.3158 0.8288 0.8288 0.5862 0.5656
3 A1.C3 - A1.C2 1.1828 0.8589 0.6051 0.6051 0.6051
$`Multiple comparison test (factor 2 in levels of factor 1)`$`factor_2 in A2`
pair contrast p(tukey) p(snk) p(duncan) p(t)
1 A2.C2 - A2.C3 1.3608 0.8182 0.5526 0.5526 0.5526
2 A2.C2 - A2.C1 2.2883 0.5751 0.5751 0.3481 0.3231
3 A2.C3 - A2.C1 0.9275 0.9104 0.6846 0.6846 0.6846
$`Residual analysis`
$`Residual analysis`$`residual analysis`
values
p.value Shapiro-Wilk test 0.6960
p.value Bartlett test (factor_1) 0.5441
p.value Bartlett test (factor_2) 0.6041
p.value Bartlett test (treatments) 0.8490
coefficient of variation (%) 10.5700
first value most discrepant 18.0000
second value most discrepant 16.0000
third value most discrepant 6.0000
$`Residual analysis`$residuals
1 2 3 4 5 6 7
-3.8008383 -0.6650073 3.8724965 -2.0512987 -1.5985339 4.2431817 0.7811775
8 9 10 11 12 13 14
-2.2518183 -1.3463467 -2.0819696 3.2036886 1.6952685 0.2874814 1.5621517
15 16 17 18 19 20 21
-1.2665734 4.3024939 0.7117327 -5.5972863 2.7321794 1.3546740 -1.2595765
22 23 24
-0.1692256 -2.3168874 -0.3411639
$`Residual analysis`$`standardized residuals`
1 2 3 4 5 6
-1.48588700 -0.25997574 1.51390084 -0.80192786 -0.62492549 1.65881525
7 8 9 10 11 12
0.30539092 -0.88031831 -0.52633627 -0.81391821 1.25243928 0.66274259
13 14 15 16 17 18
0.11238701 0.61070235 -0.49514996 1.68200256 0.27824241 -2.18818437
19 20 21 22 23 24
1.06810906 0.52959170 -0.49241461 -0.06615649 -0.90575620 -0.13337347
🔹 Módulo 4 – Regressão
Aula 13 – Regressão Linear
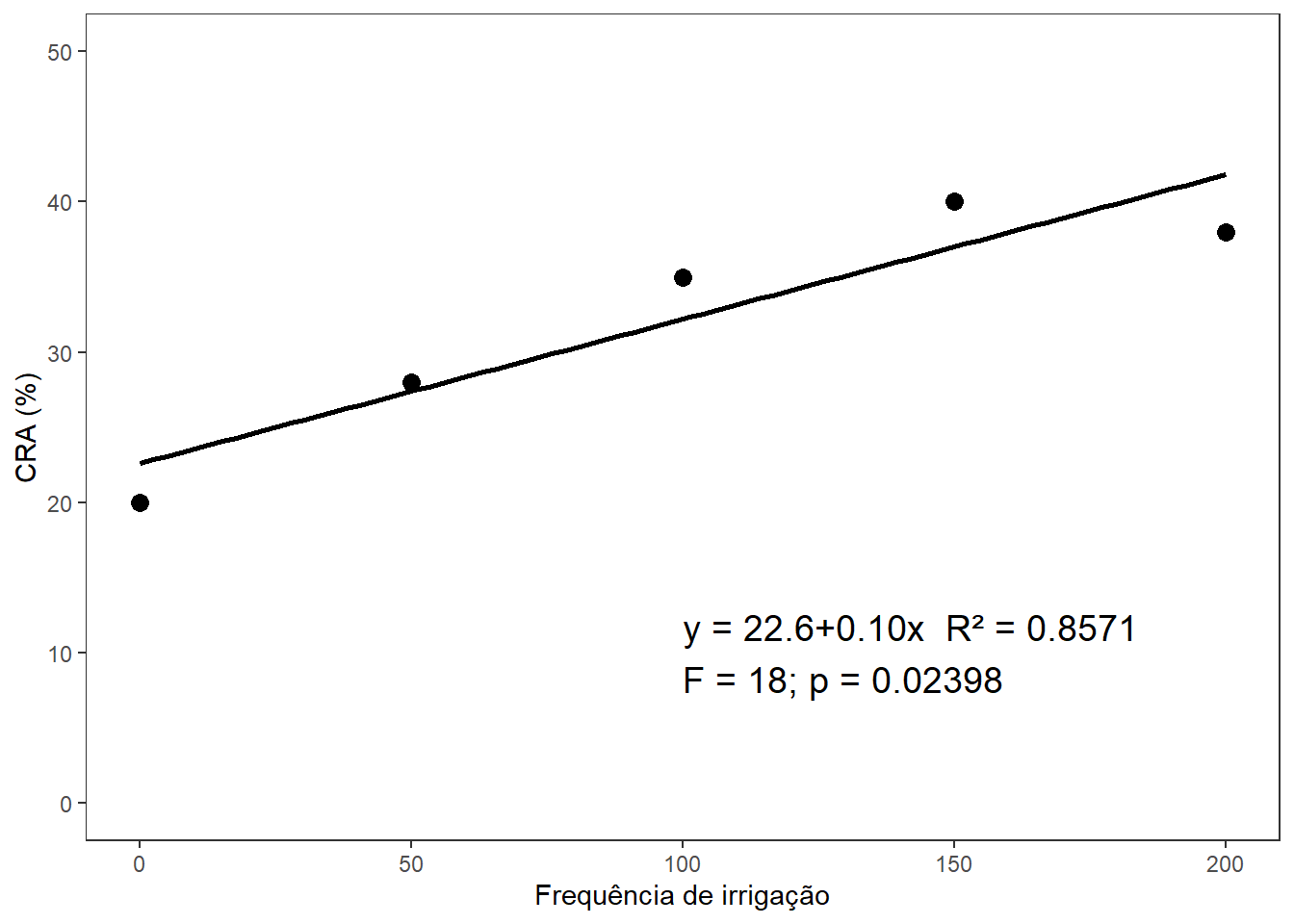
dose <-c(0, 50, 100, 150, 200)prod <-c(20, 28, 35, 40, 38)dados_reg <-data.frame(dose, prod)modelo_reg <-lm(prod ~ dose, data = dados_reg)a <-summary(modelo_reg)# Coeficientescoeficientes <-coef(modelo_reg)intercepto <-round(coeficientes[1], 2) # sem sinal extraslope <-formatC(coeficientes[2], format ="f", digits =2, flag ="+") # sempre com sinal# Estatísticas do modelor2 <-round(a$r.squared, 4)f_value <- a$fstatistic[1]df1 <- a$fstatistic[2]df2 <- a$fstatistic[3]p_value_anova <-pf(f_value, df1, df2, lower.tail =FALSE)# Equação no formato corretoequacao <-paste0("y = ", intercepto, slope, "x")legenda <-paste0( equacao," R² = ", r2,"\nF = ", f_value,"; p = ", format.pval(p_value_anova, digits =4, eps =0.001))dados_reg |>ggplot(aes(x = dose, y = prod)) +geom_point(size =3) +geom_smooth(method ="lm", se =FALSE, color ="black") +annotate("text",x =100, y =10,label = legenda,hjust =0, size =5) +labs(x ="Frequência de irrigação", y ="CRA (%)") +theme_bw() +theme(panel.grid =element_blank()) +ylim(0, 50)
`geom_smooth()` using formula = 'y ~ x'
Aula 14 – Regressão Quadrática
# Ajustar modelo de regressão quadráticamodelo_quad <-lm(prod ~ dose +I(dose^2), data = dados_reg)a <-summary(modelo_quad)a
# Coeficientes da regressão quadrática (com mais casas decimais)coef_quad <-coef(modelo_quad)intercepto <-formatC(coef_quad[1], format ="f", digits =4)linear <-formatC(coef_quad[2], format ="f", digits =4, flag ="+")quadratico <-formatC(coef_quad[3], format ="f", digits =4, flag ="+") # usei 6 casas para o termo quadrático porque geralmente é bem pequeno# Estatísticas do modelor2 <-round(a$r.squared, 4)f_value <- a$fstatistic[1]df1 <- a$fstatistic[2]df2 <- a$fstatistic[3]p_value_anova <-pf(f_value, df1, df2, lower.tail =FALSE)# Equação para legendaequacao <-paste0("y = ", intercepto, " ", linear, "x ", quadratico, "x²")legenda <-paste0( equacao," R² = ", r2,"\nF = ", round(f_value, 2),"; p = ", format.pval(p_value_anova, digits =4, eps =0.001))# Gráficolibrary(ggplot2)regressao_quad <-ggplot(dados_reg, aes(x = dose, y = prod)) +geom_point(size =3) +stat_smooth(method ="lm",formula = y ~ x +I(x^2),se =FALSE,color ="black" ) +annotate("text", x =50, y =10, label = legenda, hjust =0, size =5) +labs(x ="Dose", y ="Produção") +theme_bw() +theme(panel.grid =element_blank()) +ylim(0, 50)# Exibir gráficoregressao_quad
🔹 Módulo 5 – Relatórios e Projeto Final
Aula 15 – Relatórios com RMarkdown
Este próprio arquivo é um exemplo.
Pode ser exportado em HTML, Word ou PDF.
✅ Projeto Final
Analise um conjunto de dados agrícolas (real ou fornecido):
- Estruture os dados no Excel/CSV.
- Importe para o R.
- Realize ANOVA (com aov(), ExpDes.pt, easyanova e rstatix).
- Teste pressupostos.
- Se necessário, ajuste modelos de regressão.
- Gere gráficos com ggplot2.
- Organize os resultados em relatório RMarkdown.